
SWIRL is the AI Infrastructure Software that you need
AI infrastructure software is essential for deploying on-premises AI solutions. And in this post, we discuss the possibilities of SWIRL AI Connect and how it can enable you to
AI infrastructure software is essential for deploying on-premises AI solutions. And in this post, we discuss the possibilities of SWIRL AI Connect and how it can enable you to

While foundational in many data management strategies, the ETL process involves transferring large amounts of data into a centralized store. This operation is both resource-intensive and costly, as it requires substantial computational and storage capabilities. And in this article we discuss the case against ETL systems, in AI Architectures.

The adoption of AI in the enterprise is not without its challenges. As organizations rush to integrate AI into their operations, they often overlook critical aspects that can lead to significant risks, and this is why we have to focus on a set of principles that will dictate the next generation of AI apps in the enterprise.

SWIRL AI Connect allows for instant deployment of AI Models. In this post, Sid tries out Llama 3 with SWIRL.

A Reader Large Language Model (LLM) is an AI designed to understand and analyze text. Unlike LLMs that generate text, Reader LLMs focus on reading and making sense of existing language.

AI Infrastructure Software is an umbrella term for a software infrastructure that seamlessly integrates AI capabilities while prioritizing security, safety, and access control. It operates as a middle layer between data, AI infrastructure, and large language models (LLMs), ensuring that end-users can harness the power of AI without compromising data security or compliance.

SWIRL is moving towards bringing AI to the data instead of data to the AI. Breaking conventional barriers and utilizing Reader LLMs and eliminating the need for extensive data movement, SWIRL enables enterprises to generate valuable AI insights without complex IT projects.

Discover how SWIRL AI Connect can help your business stay ahead of the curve in the ever-evolving world of artificial intelligence. With cutting-edge capabilities and a focus on data-driven decision-making, this advanced infrastructure is the key to unlocking new levels of efficiency, innovation, and customer satisfaction.

Improve your organization’s knowledge flow with these 5 essential knowledge management strategies. Optimize information access and foster a knowledge-sharing culture

Discover how to implement generative AI for increased efficiency and innovation, while ensuring security. Learn about use cases, best practices, and how Swirl can help.

In this post, Simson explains what a vector database is and why Dr. Low’s article on Vector Database says you don’t need one and provides context to Dr. Low’s answer.

Dive into the fascinating world of Large Language Models (LLMs) and uncover the science behind these powerful AI systems that can generate human-like text and even create images. Explore their evolution, inner workings, and the potential they hold for the future.

Cosine similarity is a metric that measures how similar two entities (vectors) are irrespective of their size. Commonly used in high-dimensional positive spaces, it can be helpful in various applications, including data analysis, information retrieval, and understanding the relationship between documents in text processing.

Generative AI promises to revolutionize enterprise search, empowering organizations to extract critical insights, foster innovation, and optimize decision-making.

Critical information resides in far-flung corners: structured databases, departmental silos, and scattered unstructured files. While this data holds immense potential, discovering the right insights often requires a tedious process of piecing together fragments from various sources.

The concepts of Generative AI, Machine Learning, and Deep Learning are fueling an explosion of exciting possibilities, yet some need for clarification about how they relate and differ may persist. Let’s break down these powerful branches of AI to get a clearer picture.

Knowledge management (KM) is the process of creating, sharing, using, and managing the knowledge and information of an organization. It refers to a multidisciplinary approach to achieving organizational objectives using the best knowledge.

Semantic similarity measures how similar two pieces of text are in meaning rather than just the words used. It is a branch of artificial intelligence and natural language processing that deals with understanding the meaning of words and phrases.

A data silo refers to a repository of data controlled by a particular department, team, or system within an organization.

The sheer volume of online data necessitates precision in search results. Search relevancy is the essential tool that filters through the informational deluge, presenting users with the most accurate and applicable content.

A search index is a data structure that improves the speed of data retrieval operations on a database by providing quick lookups to the data records.

A vector database stores numerical representations of texts, images, and videos.

Cloud computing has undeniably transformed the way organizations approach IT infrastructure. Among the prevalent cloud models, private clouds (internal or corporate clouds) are rapidly gaining traction due to their emphasis on security, control, and customization. This article delves into the fundamentals of private cloud computing, its architectural components, advantages, drawbacks, various types, use cases, and comparisons with other deployment models.

Enterprise search involves creating a massive, unified index of your organization’s data. This index is a comprehensive library catalog, encompassing everything from documents on file servers to email archives and customer records. When a user queries, the enterprise search engine consults this index for results.

Machine learning (ML), a transformative branch of artificial intelligence, has transitioned from theoretical realms to real-world impact across industries. Instead of rigid rules, machines learn from examples and data to find patterns on their own.

A search engine is a complex software system meticulously designed to discover, interpret, and organize internet content.

Enterprise search is a technology that helps employees find information across their organization’s data silos. It can search various sources, including file shares, databases, email, and collaboration platforms. However, traditional enterprise search solutions often need to be revised, delivering irrelevant results or requiring users to know exactly what they want.

Embrace the power of AI-driven hosted search for your business. Learn how it boosts productivity, simplifies deployment, and integrates seamlessly with Azure – with AWS and GCP support on the way.

Discover how Retrieval Augmented Generation (RAG) enhances language models. Find out its real-world applications and how Swirl tackles RAG with metasearch for unparalleled flexibility.

Demystifying enterprise search and federated search – understand the differences, benefits, and use cases with an eye on how Swirl Search empowers both strategies.

Imagine all your business data – every file, email, and database entry – trapped in separate rooms. Searching means running from room to room. Frustrating, right? Federated enterprise search builds a hallway connecting everything; one search box to find it all.

Federated search is a technique used to simultaneously search multiple data sources, data warehouses, etc. A federated search engine is a powerful tool that lets you search across multiple databases, websites, chats, internal articles, or information systems all at once, using just one query.

Unified search is an advanced strategy consolidating data from diverse sources (databases, documents, web pages) into a single, easily accessible interface. Users execute a single query, spanning various repositories, streamlining the search process and maximizing efficiency.

A metasearch engine is an information retrieval solution that connects to multiple search engines to fetch results for the same query and then produce a blended result set. Metasearch engines take a query from a user and immediately distribute the query across search engines for results. After gathering the data, the metasearch engine ranks and displays the results. Best in class metasearch or federated solutions will normalize relevancy from the disparate sources.

Swirl releases version 3.2.0. With this, we continue our march towards a secure, tight, air-gapped enterprise-grade unified search and data access platform, which operates within your enterprise firewall, and with your private large language model.
Swirl is available in Azure with a 30 30-day free Trial.

This article showcases the Swirl Reference Architecture for Real-Time, AI-Powered Enterprise Search.

We have the new AutomaticPayloadMapperResultProcessor which automatically organizes the data from search providers into the Swirl system, so you don’t have to map out the results manually. With this, your search queries would be easier behind the scenes, and you’ll be more productive at work.

Bringing AI enabled search to the enterprise. We know that AI is important for our organizations, but the real problem is how we can empower our organizations with AI. Swirl provides a solution for that.

Adam sets up to write about his journey with Swirl, and how he’s planning to shape the future of Enterprise search with Swirl. And a moment to reflect on Swirl’s journey over the past nine months and celebrate the launch of Swirl on Azure Marketplace for private cloud deployment.

AI-powered enterprise search for secure private cloud retrieval augmented generation. Swirl AI-powered federated metasearch enables enterprise users to rapidly locate, retrieve, and act on enterprise data, applications, and insights through an intuitive search interface.

Chris Biow joins in as Head of Federal Sales at Swirl. Biow will expand Swirl’s presence and impact in the federal market, where AI demand is growing rapidly.

Swirl Breaks Cookie Cutter Enterprise Search Approaches with its unified searching capabilities along with artificial intelligence integration.

Swirl nails the enterprise search and provides the best search results from a wide array of data sources.

Swirl 3.1.0, the latest update to the open-source search enterprise search platform, brings several exciting features, seach providers, etc.

This blog talks about how Swirl uses Swirl at work, which is incredibly compelling.

Why large language matters and the context between word also matters when it comes to search, ranking and relevancy.

The traditional approach is the lift and shift of data from one container to another. It is a big problem in many cases, and Swirl serves as the best solution to this problem.

Searching through your entire enterprise? Swirl Search offers viable solutions for this. It is the AI Driven Enterprise Search Solution. Perform federated search through all of your enterprise with easy.

Swirl is thrilled to announce the addition of five distinguished professionals to its Board of Advisors.

Swirl 3.0 introduces new features like Retrieval Augmented Generation, LLM Swapping & more. Read this blog to know more.

US Government Agencies can evaluate and deploy Swirl today without cost by utilizing Swirl’s Open Source offerings. Please checkout the blog for more information.

Swirl version 3.0 is coming up and we have a webinar up and running for you to join.

Learn how to deploy Swirl in Azure securely and understand Swirl’s security framework, compliance and KYC with Swirl.

This blog covers the second part of Swirl Security Overview (User Data, Metadata, and Credentials). This is a three-part series that guides you about Swirl’s security.

This series of blogs will give you a security overview of Swirl. How Swirl works behind the scenes, and how to securely deploy Swirl in Azure.

Contribute to Swirl in this Hacktoberfest 2023. Win swags, code and learn about Swirl.

This release adds SearchProviders for ServiceNow, Hacker News and Google News. We’ve also validated Swirl on the latest stable Python version (3.11.5) and updated our Dockerfile image to the latest stable Debian release (Bookworm).
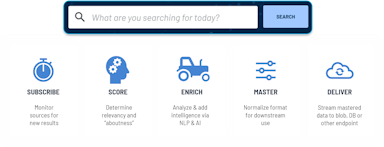
Software companies can reduce churn and increase engagement by adding generative AI. However, challenges such as lack of data, security concerns, and integration with existing processes can make it difficult. When successfully embedded, AI can create differentiation and unlock various use cases. Swirl, an open-source tool released on GitHub under Apache 2.0, allows for quick […]
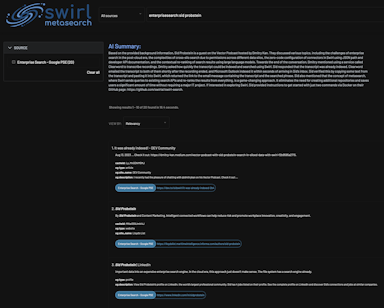
Swirl is delighted to announce our end-to-end enterprise support for using enterprise content, such as Microsoft 365 and ChatGPT, to get current generative insights from your own data, quickly and safely. Swirl Retrieval Augmented Generation (RAG) combines metasearch, relevance ranking, authentication, prompt creation and ChatGPT response, with citations. Per OpenAI’s privacy policy the prompt is not used for training unless you opt-in. Deploy in minutes via Azure.

It is understood that “Any company that creates more than $10 billion in shareholder value does one of two things: extend time (more time, saving time) or enhance time.” Time is priceless. Swirl recently released version 2.5 featuring a performance benchmark showing a median search time of ~3 seconds across 12 sources. In layman’s terms, […]
Team Swirl is thrilled to announce the General Availability of Swirl 2.5! The theme for this release is performance. Configured with 12 SearchProviders, Swirl 2.5 supports up to 15 queries/second on a Standard F16s v2 server (16 vcpus, 32 GiB memory) with a median response time of 3 seconds. Swirl 2.5 also includes SearchProviders for […]
Team Swirl is delighted to announce General Availability of Swirl Metasearch 2.1! This version features the new Galaxy Search Interface with Dark Mode: It also includes numerous refinements such as: Version 2.1 also comes with SearchProviders for GitHub Code, Commits, Pull Requests, and Issues. Please visit our Release 2.1 page in the public repo for full details! Search Developers, […]

One of the most important elements of Swirl Metasearch is the SearchProvider. In this video, Erik Spears and Sid Probstein from Swirl take a good look at SearchProviders. Some of the details covered in the video include: SearchProviders also contain: Although SearchProviders are stored in the Swirl configuration database, they can be viewed and edited […]

Curious about Metasearch? Want to know how Swirl works? And why it turns out to be such a game-changer in the post-pandemic, “really in cloud now” era? Here’s a new video that covers it all.

Curious about Metasearch and why your company should be using it to solve cross silo search problems? In this video Sid Probstein, creator of Swirl Metasearch, explains why it represents a game changer for the enterprise!
Check out this short post in which Sid Probstein, creator of Swirl Metasearch, explains the main features of Swirl.
We are delighted to announce the general availability of Swirl Metasearch 2.0!
This major leap forward in functionality makes it easier than ever to solve cross-silo Enterprise Search problems quickly and securely — without extracting or moving any data.
I’ve been fortunate to work in search a few times now. And I believe it continues to be the most human way of interacting with data. But search changes constantly; Brin and Page were chasing the Star Trek computer; they ended up with an ad engine. Search is tricky, and not just because of the […]
Contact Swirl to learn more